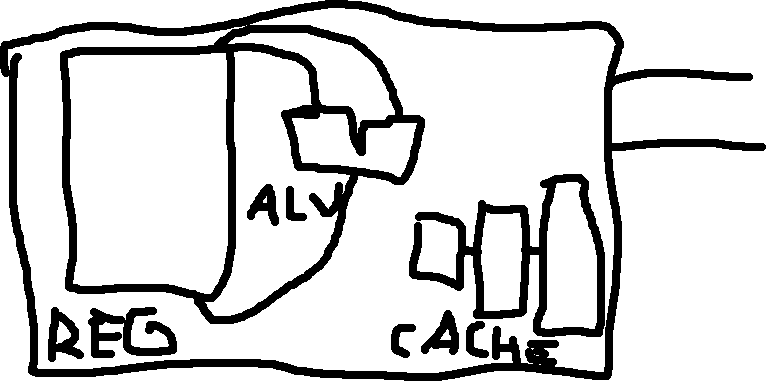
Constructing a CPU:
On I/O: There are only two ways for external devices to communitate with the CPU:
- Interrupt: Stop what you’re doing and respond.
- Reject means do nothing.
- Accept means respond.
- Delay means delay.
- Polling: Periodically ask each device if they have input.
- Parallel Polling: “Does anybody have a question?”
- In this case, you have to decide on priority of responding.
Interrupt v. Polling: If a device fails, interrupt won’t catch it.
Suppose this operand format:
AC <- AC + 100The realization of this may result in a huge delay if the same memory cell is required for the next instruction.
Thus, it’s better to use an intermediate register to save the possible required data.
Operation Operand1, Operand2, Operand3, Next InstructionOperation Operand1, Operand2, Operand3Operation Operand1, Operand2Operation OperandOperation OperandFetch: During the fetch cycle, the CPU retrieves the instruction from memory.
Instruction Fetch:
- An instruction pointed by the PC is loaded from main memory into the PC before getting incremented by 4, because the word size is 4 bytes.
Until now, we’ve been using specialized modules for fetching, decoding, executing, and writeback.
Now, suppose we instead get 4 modules who can do all operations.
| F1 | D1 | E1 | WB1 | |
|---|---|---|---|---|
| F2 | D2 | E2 | WB2 | |
| F3 | D3 | E3 | WB3 | |
| F4 | D4 | E4 | WB4 | |
| F5 | D5 | E5 | WB5 | |
| F6 | D6 | E6 | WB6 | |
| F7 | D7 | E7 | WB7 | |
| F8 | D8 | E8 | WB8 |
Limitation: Instruction dependency. You can’t write a program where all the instructions aren’t related.
The main memory is very slow, one solution is to add an external cache.
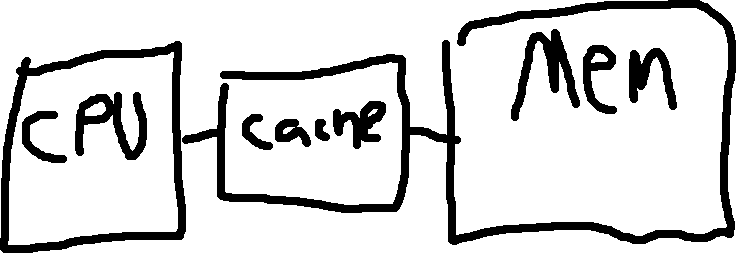
Suppose it takes:
The average access time (AAT) would be
h\tau_1 + (1-h)t_2
For example, suppose h = 0.9, t_1 = 1, t_2 = 100
\text{AAT} = 0.9 \times 1 + 0.1 \times 100 = 10.9
Professor’s Personal Experience: In the real world, the hit ratio lies between 0.7 and 1.0
The lie: If we have to go to main memory, we’ll actually need to go in and pull the data out, which means we’ll be traveling across t_1 and t_2
\boxed{ \text{AAT: } h\tau_1 + (1-h)(t_1 + t_2) }
If we plug in h = 0.9, t_1 = 1, t_2 = 100, we’d get:
0.9 * 1 + (0.1)(101) = 11
Q: Why can’t we put the cache in the CPU?
A: Space.
CISC v. RISC:
- CISC: Complex Instruction Set Computers
- RISC: Reduced Instruction Set Computers
ADD AX,1 # ADD is a general instruction INC AX # INCREMENT is not a general instruction
- INC would be provided in CISC, but not in RISC.
RISC can increase space in the CPU.
- 80% of a program is typically with 20% of the instruction set.
- And any missing functionality can be constructed if needed.
- This is why we are moving towards RISC in the real-world.
By switching to CISC, we can put cache in the CPU.
Not only that, but we can split up the cache into a smaller and bigger cache:
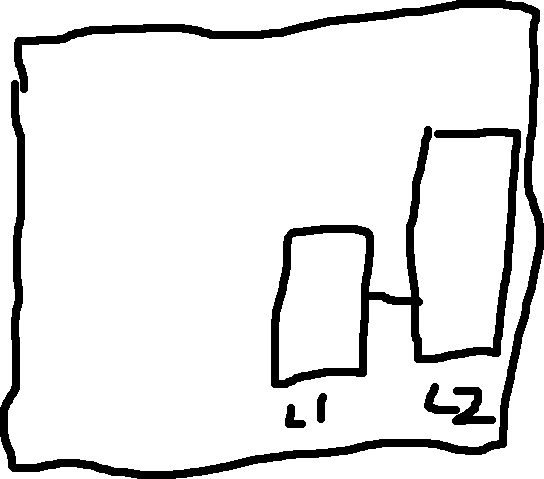
Accessing cache is random.
On CAM
- Suppose we have 8 memory cells.
- With three bits, we can address every cell (0, 1, …, 7)
- All memories work like this, but CAM has the ability to search the memory for content and get the address.
- e.g., CAM(00001001) => 0x6. If the content can be found in multiple banks, the result will depend on the algorithm used.
The technology of the cache and the CPU must be the same. * e.g., if the CPU is 1nm, the cache must also be 1nm. * Technically, the CPU can be larger than the cache, but it’ll be a waste of money. + e.g., 1nm CPU and 0.5 nm cache is valid, but wasteful.